
From PDF to scorecard.
Evidence at every step.
Most hiring platforms treat resumes as blobs of text and scores as black boxes. Intelletto is different. Every resume flows through a 12-stage AI pipeline that extracts, normalizes, validates, and scores with full evidence and audit trail.
Intelletto.ai turns messy documents into structured, explainable hiring decisions. From AI-generated job descriptions to lossless parsing, 55,000-skill normalization, five validation gates, and 8-bucket weighted scoring — every step is traceable, auditable, and deterministic.
JD Orchestrator & AI Generation
Create complete, consistent job descriptions in minutes — not days.
Every JD starts with AI. Give it a job title and company context, and Gemini generates 12-18 required hard skills, soft skills calibrated to seniority, knockout questions with expected answers, interview questions with follow-ups, and a candidate-facing job description. The JD Orchestrator lets you refine every detail across 11 structured screens — from basics and skills taxonomy to company EVP and candidate intake requirements. Every JD gets a unique 6-character reference code, version history, and draft/live lifecycle.
- Stop writing JDs from scratch — AI generates domain-specific content in seconds.
- Skills are drawn from a 55,000+ term taxonomy — not guesswork.
- Knockout and interview questions come pre-built with expected answers.
- Candidate-facing JD and landing page auto-generated from the same model.
- Consistent quality across every requisition — no more copy-paste drift.
- Faster time-to-post — from blank to live in under 10 minutes.
- Better candidate targeting with seniority-aware skill requirements.
- Reusable templates that improve with each hiring cycle.

Resume Intake & Pool Management
Candidates flow in automatically. You focus on who to advance.
Resumes arrive through multiple channels: bulk GCS upload into organized RESUME-POOL folders by JD code, direct upload through the intake suite, or candidate self-submission via landing pages. Each document is automatically registered, checksummed for dedup protection, and assigned to the correct JD based on its GCS directory path. The pool system supports three processing modes: Mode A builds a talent pool without scoring, Mode B activates pool candidates against a specific JD, and Mode C runs the full 12-stage pipeline end-to-end.
- Drop PDFs into a GCS folder and they're automatically assigned to the right JD.
- Candidate landing pages let applicants self-submit with LinkedIn and portfolio links.
- Pool modes let you build talent pools first, then activate when ready.
- Duplicate detection catches re-submissions before they waste pipeline time.
- Zero manual intake routing — JD assignment is automatic from folder structure.
- Flexible pipeline modes adapt to sourcing vs active hiring workflows.
- Audit trail from first touch — every document tracked from upload to score.
- Scale to thousands — 2,500+ resumes processed in a single batch run.

Document AI & Gemini Extraction
Every word, date, and achievement captured — nothing summarized, nothing lost.
Each resume PDF is sent directly to Gemini 2.5 Flash with a strict response schema that enforces consistent JSON output. The extraction captures work history with exact dates and verbatim achievements, skills categorized as technical and soft, education with institutions and fields, certifications with issuers and dates, and languages with proficiency levels. The response_schema parameter constrains Gemini at the API decoding level — preventing the inconsistent JSON formats that caused zero-skill failures in early versions. Every extraction is checksummed and cached for cost efficiency.
- No manual data entry — Gemini reads the full PDF layout including tables and columns.
- Skills always come back in a consistent format — no more parsing surprises.
- Cached extractions mean reprocessing is instant and free.
- Works with any PDF format — single column, multi-column, creative layouts.
- Lossless extraction — every bullet point, date, and certification captured.
- Schema enforcement eliminates 100% of format inconsistencies (down from 15.5% failure rate).
- 50% cost reduction via extraction caching and batch API.
- Sub-minute processing per resume with Gemini 2.5 Flash.

Skills Normalization
Whether they say 'React.js', 'ReactJS', or 'React' — we know it's the same skill.
Raw skill terms from extraction are matched against a 55,000+ hard skill taxonomy with 63,000+ aliases. Match types include exact (1.0 confidence), fuzzy (0.65+), and semantic matching. The normalization also scans work experience descriptions for taxonomy terms that candidates didn't explicitly list as skills. Certifications are expanded into their constituent skills via the certification-to-skill map. The result: a canonical skill profile that scoring can reliably match against JD requirements.
- Candidates aren't penalized for using different terminology than the JD.
- Certification holders get credit for implied skills automatically.
- Skills found in job descriptions are matched even when not listed in a skills section.
- Quality alerts flag when normalization confidence is low.
- Fair matching regardless of how candidates describe their abilities.
- Taxonomy grows over time — 601 new skills added from real-world resume data.
- Match accuracy above 99% with combined exact + fuzzy + semantic matching.
- Audit trail shows exactly how each raw term was normalized.

Data Fusion & Enrichment
The resume is the start. Enrichment adds the evidence.
When candidates provide URLs — LinkedIn profiles, GitHub repos, portfolio sites, personal websites — the enrichment stage fetches and parses each one. Gemini synthesizes the combined evidence into enriched skill profiles with verified vs unverified flags. Every fetch is logged with source, URL, status, and character count. Private IP addresses and internal networks are blocked via DNS resolution and SSRF protection. Skills identified from external sources but without direct evidence quotes are kept with downgraded confidence, not dropped entirely.
- Website and portfolio content is automatically parsed for additional skills.
- Every enrichment source is logged — you can see exactly what was found where.
- Candidates with rich online presence get fuller, fairer profiles.
- Failed fetches are logged as warnings, not silent drops.
- Richer candidate profiles from public data — without manual research.
- SSRF-protected — private networks and internal IPs are blocked.
- Evidence traceability — every enriched skill links back to its source.
- Competitive advantage in assessing candidates with strong public portfolios.

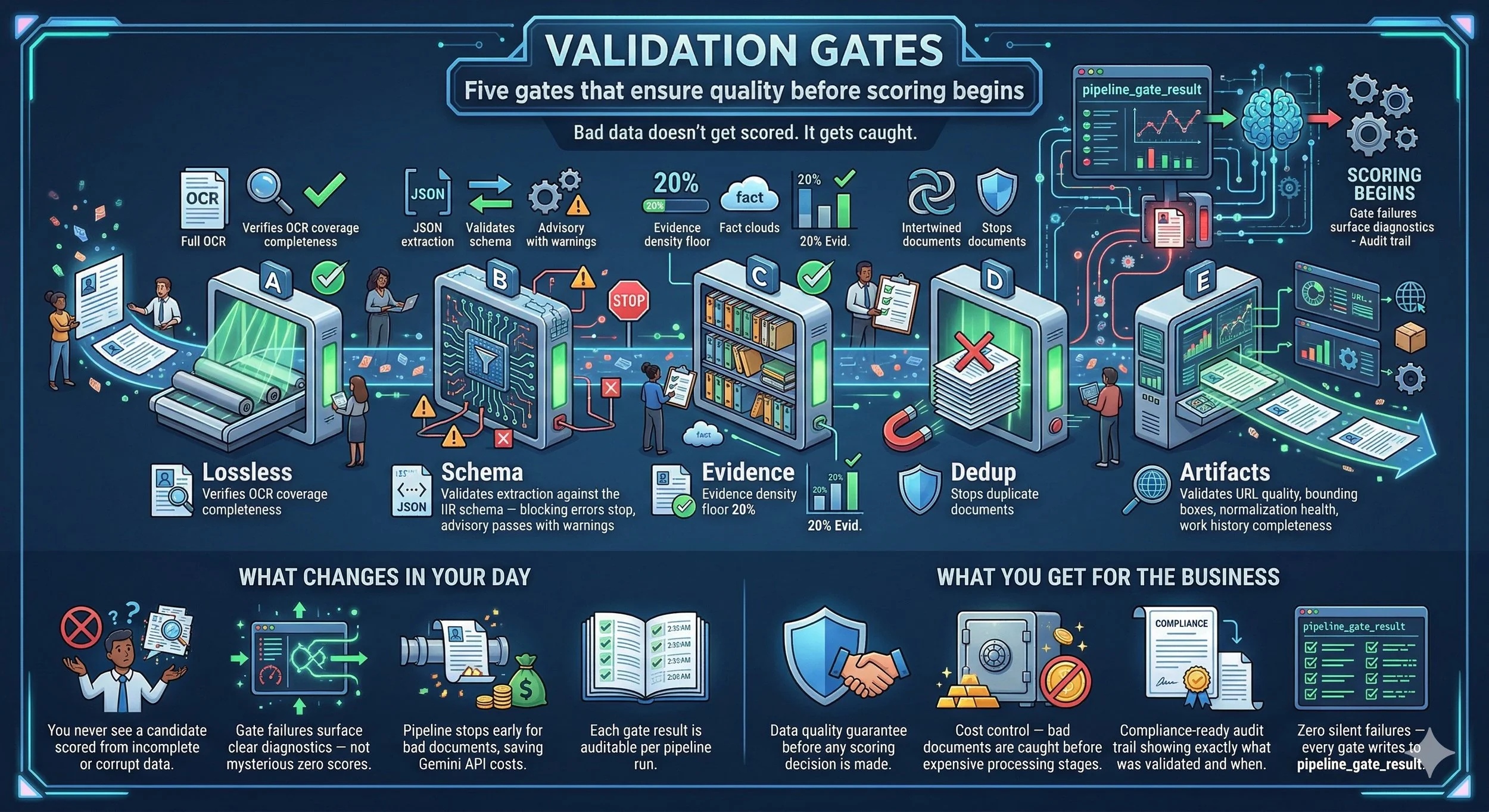
Validation Gates
Bad data doesn't get scored. It gets caught.
Five validation gates control pipeline progression. Gate A (Lossless) verifies OCR coverage completeness. Gate B (Schema) validates the extraction against the IIR schema — blocking errors stop the pipeline, advisory issues pass with warnings. Gate C (Evidence) checks per-section fact coverage with a 20% evidence density floor. Gate D (Dedup) stops duplicate documents. Gate E (Artifacts) validates URL quality, bounding boxes, normalization health, and work history completeness. A gate failure at the wrong stage would silently pass bad data or catastrophically block all resumes — so each gate writes its pass/fail result to the audit trail.
- You never see a candidate scored from incomplete or corrupt data.
- Gate failures surface clear diagnostics — not mysterious zero scores.
- Pipeline stops early for bad documents, saving Gemini API costs.
- Each gate result is auditable per pipeline run.
- Data quality guarantee before any scoring decision is made.
- Cost control — bad documents are caught before expensive processing stages.
- Compliance-ready audit trail showing exactly what was validated and when.
- Zero silent failures — every gate writes to pipeline_gate_result.
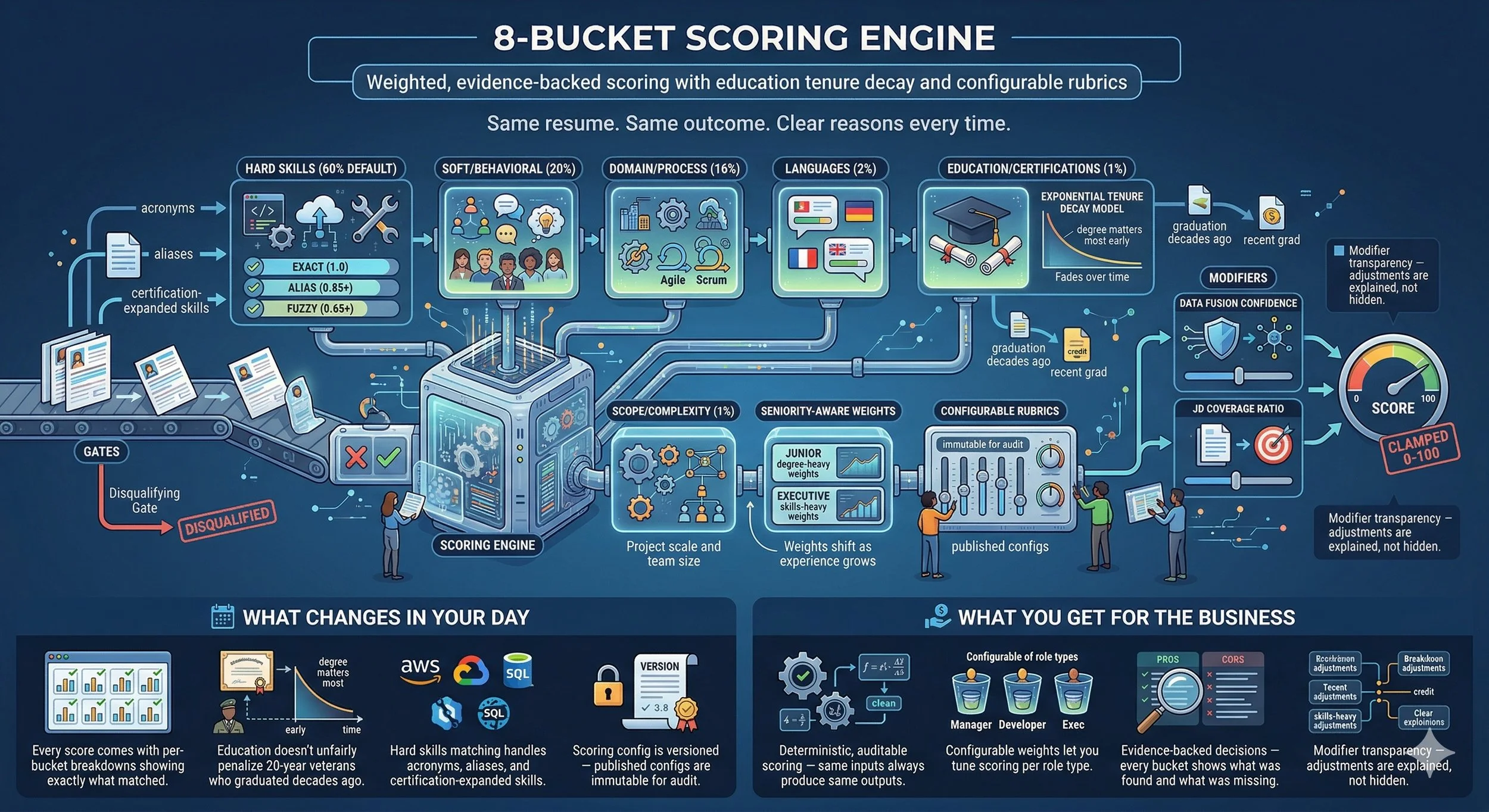
8-Bucket Scoring Engine
Same resume. Same outcome. Clear reasons every time.
Candidates are scored across 8 weighted buckets: Hard Skills (60% default), Soft/Behavioral (20%), Domain/Process (16%), Languages (2%), Education/Certifications (1%), Scope/Complexity (1%), and more. Hard skills matching uses three tiers: exact (1.0), alias (0.85+), and fuzzy (0.65+). Education scoring uses an exponential tenure decay model — a degree matters most early in a career and fades as experience grows. Seniority-aware weights shift from degree-heavy for juniors to skills-heavy for executives. Gates run first: if a disqualifying gate fails, the candidate is marked DISQUALIFIED before bucket scoring begins. Two modifiers — data fusion confidence and JD coverage ratio — adjust the final score up or down, clamped 0-100.
- Every score comes with per-bucket breakdowns showing exactly what matched.
- Education doesn't unfairly penalize 20-year veterans who graduated decades ago.
- Hard skills matching handles acronyms, aliases, and certification-expanded skills.
- Scoring config is versioned — published configs are immutable for audit.
- Deterministic, auditable scoring — same inputs always produce same outputs.
- Configurable weights let you tune scoring per role type.
- Evidence-backed decisions — every bucket shows what was found and what was missing.
- Modifier transparency — adjustments are explained, not hidden.
Recruiter Artifacts
Everything a recruiter needs, ready before they even ask.
After scoring, the pipeline generates three recruiter-facing artifacts. The Intelletto Resume is a standardized, lossless rendering of the candidate's full profile — always longer than the source document, never truncating achievements or advisory roles. The Candidate Dashboard shows the score breakdown, strengths, gaps, red flags, and a plain-language explanation of why this candidate scored the way they did. The Interview Brief generates evidence-derived probes targeting technical gaps, behavioral signals, and risk flags — all without calling Gemini, using the scoring evidence directly.
- Open any candidate and see a complete, formatted profile — no PDF juggling.
- Dashboard explains the score in plain language — not just a number.
- Interview prep is automatic — targeted questions based on actual gaps.
- Cover letter sentiment analysis when a cover letter is provided.
- Faster recruiter review — everything on one screen.
- Consistent candidate presentation regardless of original resume format.
- Interview quality improves with evidence-derived, gap-targeted questions.
- Hiring manager confidence from clear, explainable scoring rationale.

Culture Fit System (CFS)
Hire for values, not just skills.
The Culture Fit System configures culture pillars, measures alignment through structured assessments, and feeds results back into scoring. HR People Analytics shows culture signal trends across teams. Manager task lists drive culture check completion. Recruitment playbooks export role-specific culture criteria. The system measures fit against stated values — not demographic similarity — ensuring diversity-safe culture assessment.
- Culture pillars are configurable per team and role level.
- Managers get clear task lists for culture check completion.
- Recruitment playbooks export culture criteria for hiring panels.
- Employee feedback loops improve culture definitions over time.
- Predictive retention — culture-aligned hires stay longer.
- Diversity-safe assessment based on values, not demographics.
- Cross-team analytics show where culture signals diverge.
- Continuous improvement as feedback refines culture definitions.

Recruiter Command Center
Stop context-switching. Start deciding.
The Command Center is where recruiters live. It shows open positions with candidate counts, score distributions, and pipeline health at a glance. Each JD displays its top candidates ranked by score with STRONG/BORDERLINE/RISK bands. Recruiters can drill into any candidate's dashboard, advance candidates to the longlist, schedule interviews, or reject — all without leaving the workspace. Cross-JD fit analysis shows when a candidate might be better suited to a different open role.
- One screen shows all your open positions and where candidates stand.
- Score bands (Strong/Borderline/Risk) make triage instant.
- Advance, hold, or reject candidates with a single click.
- Cross-JD fit catches candidates you might miss.
- Reduced time-to-shortlist with pre-ranked, pre-explained candidates.
- Better pipeline visibility for hiring managers and stakeholders.
- Consistent decisions driven by data, not gut feel.
- Cross-JD matching maximizes every candidate who enters the system.

Longlist Panel
Everyone sees the same board. No one asks 'where are we?'
The Longlist Panel is a Kanban-style board with swim lanes for each hiring stage: New, Shortlisted, Interview Scheduled, Interview Complete, Offer, Hired, Rejected, Withdrawn. Candidates move between lanes with full score context preserved. Each board is tied to a JD, showing candidate counts, score snapshots, risk flags, and customer exposure indicators. Recruiters, hiring managers, and stakeholders share the same view — eliminating the 'where is this candidate?' question.
- Drag-and-drop candidates between hiring stages.
- Score and risk context travels with the candidate.
- Filter by score range, risk flag, or customer exposure.
- One board per JD — no confusion about which pipeline you're looking at.
- Full pipeline transparency across all stakeholders.
- Stage-level metrics show where candidates get stuck.
- Audit trail for every status change.
- Shared visibility eliminates hiring manager follow-up emails.

Pipeline Operations & Monitoring
Know what's processing, what's stuck, and what needs attention.
The Pipeline Orchestrator shows real-time telemetry across all 12 stages. Every phase event — started, completed, failed — is recorded with duration, error codes, and gate snapshots. The health endpoint checks DB connectivity, pool stats, queue lag, GCS readiness, and Gemini key presence. Dead letter queues catch documents that exhaust retries. Exponential backoff prevents retry storms. Pipeline monitoring dashboards show throughput, error rates, and stage latency across time.
- See exactly which stage each document is in — right now.
- Failed documents show clear error codes and diagnostics.
- Dead letter queue prevents stuck documents from blocking the pipeline.
- Health check shows system status at a glance.
- Operational confidence with full pipeline observability.
- Fast incident response with stage-level error telemetry.
- Capacity planning from throughput and latency metrics.
- SLA tracking with latency reports per pipeline stage.

Scoring Configuration & Administration
The scoring engine works for you — not the other way around.
The Scoring Console lets you configure bucket weights, gate thresholds, and modifier budgets. Published configs are immutable — edits create new versions. The Skills Maintenance console manages the 55,000+ hard skill taxonomy and 63,000+ aliases. Vendor Certifications map credentials to skill expansions. EOR and Customer maintenance manage the multi-tenant company hierarchy. User management controls access and roles. Every configuration change is versioned and auditable.
- Adjust scoring weights per role type without developer involvement.
- Skills taxonomy is searchable and editable in the browser.
- Certification-to-skill mappings expand candidate profiles automatically.
- Published scoring configs are locked — you can always explain a past score.
- Self-service configuration reduces dependency on engineering.
- Version-controlled scoring ensures audit compliance.
- Growing taxonomy adapts to new technologies and skill terminology.
- Multi-tenant architecture supports multiple customers and EORs.

Offer & Hire
The best candidate said yes. Now make sure nothing falls through the cracks.
Offers are where momentum either becomes a hire—or becomes a regret. This stage turns the final decision into a clean, trackable workflow: compensation benchmarking from the inference engine provides P25/P50/P75 salary bands by seniority, country, and industry. Offer approval workflows route through hiring managers with full scoring context attached. Candidate communication templates maintain employer brand consistency. The system tracks offer acceptance, negotiation, and withdrawal rates — feeding back into JD calibration and scoring refinement for future roles.
- Compensation benchmarks are ready before you draft the offer.
- Approval workflows route automatically with full candidate context.
- Offer templates maintain brand voice across every communication.
- Acceptance and withdrawal tracking closes the feedback loop.
- Competitive offers informed by market compensation data.
- Faster time-to-hire with streamlined approval chains.
- Higher acceptance rates from consistent, professional candidate experience.
- Continuous improvement as offer outcomes feed back into scoring calibration.