
Intelletto.ai Resume Scoring
Production System Reference
Version Block
- document_version: 1.0.0
- document_effective_date: 2026-04-04
- status: Production System Reference
- pipeline_version: v3 (Cloud Run, revision 276+)
- scoring_engine_version: 1.0.0
- scoring_config_schema_version: scoring_config.schema.v1
- scorecard_schema_version: scorecard.schema.v1
- model_id (Gemini): gemini-2.5-flash (bounded inference only, with
response_schemaenforcement) - taxonomy_snapshot_id: taxsnap_<ulid> (immutable snapshot reference used for scoring run)
- test_suite: 747 tests passing (v3: 101, v2 reference: 327, integration: 319)
Ownership and Governance
- Executive Owner: Scott Darrow
- Product Owner: Scott Darrow
- Engineering Owner: Intelletto Platform Engineering
- Change control rule: All changes to scoring config schema, scorecard schema, or bucket rubrics require version bump, backward compatibility statement, and regression test updates (golden packs).
Document Section Index
- Section 1: System Architecture (v3)
- Section 2: 8 Scoring Buckets (Formulas and Implementation)
- Section 3: Scoring Gates
- Section 4: JD Skill Requirements Loading
- Section 5: Modifiers
- Section 6: Scoring Config Lifecycle
- Section 7: Database Schema
- Section 8: API Endpoints (v3)
- Section 9: Enhancement Endpoints
- Section 10: Scoring Runtime Workflow
- Section 11: Environment and Deployment
- Section 12: Known Gaps and P0 Status
- Section 13: Non-Negotiable Invariants
Section 1: System Architecture (v3)
1.1 Runtime Environment
- Runtime: Google Cloud Run (production:
api.intelletto.ai) - Database: Google Cloud SQL PostgreSQL (
intelletto-ai,asia-southeast1), schema:intelletto, ~169 tables - Storage: Google Cloud Storage for resume ingestion (
RESUME-POOL/) and archival - OCR: Google Document AI for layout parsing
- LLM: Google Gemini 2.5 Flash for structured extraction, enrichment, and soft signal inference (bounded inference only, always with
response_schemaenforcement) - Entry point:
v3/main.py - App factory:
v3/src/api/app.py - Local dev server:
http://localhost:8080
1.2 v3 Scoring Domain Modules
The scoring engine is organized as a domain module within the v3 architecture:
| File | Purpose |
|---|---|
v3/src/domains/scoring/score_service.py |
Primary scoring orchestration: gate evaluation, bucket dispatch, modifier computation, persistence |
v3/src/domains/scoring/config_service.py |
Scoring config lifecycle: DRAFT, PUBLISHED, DEPRECATED. Validation, publish, rollback |
v3/src/domains/scoring/models.py |
Pydantic request/response models for all scoring endpoints |
v3/src/domains/scoring/cross_jd_fit.py |
Multi-JD matching: scores candidate against multiple JDs simultaneously |
v3/src/domains/scoring/interview_brief.py |
Evidence-derived interview probes: technical gaps, behavioral signals, risk flags |
v3/src/domains/scoring/authenticity.py |
Resume authenticity scoring: date coherence, title inflation, career plausibility |
v3/src/domains/scoring/bias_audit.py |
Bias audit: age inference + gender-coded language detection (advisory only) |
v3/src/domains/scoring/comp_inference.py |
Compensation inference: P25/P50/P75 by seniority, country, industry |
v3/src/domains/scoring/jd_calibration.py |
JD difficulty calibration: score distribution analysis and difficulty index |
v3/src/domains/scoring/sector_classification.py |
Industry/sector classification: 15 NAICS-style sectors, sector continuity score |
v3/src/domains/scoring/risk_service.py |
Risk scoring and stability analysis |
1.3 Shared Scoring Infrastructure
| File | Purpose |
|---|---|
src/scoring/runtime.py |
ScorerRegistry — exact-match bucket dispatch (not substring). Routes bucket_id from config to scorer implementation |
src/scoring/education_scorer.py |
Education tenure decay model with seniority-aware weighting |
src/scoring/helpers.py |
Score-to-band mapping: STRONG / BORDERLINE / RISK with ADVANCE / REVIEW / HOLD |
src/scoring/resume_risk.py |
Resume risk signal computation |
1.4 Upstream Pipeline Stages (12-Stage)
Scoring starts only after the resume parsing pipeline completes stages 01–09 and creates a scoring_input_snapshot. The pipeline is orchestrated by Netflix Conductor (workflow intelletto_pipeline_mode_c), with workers on Cloud Run (intelletto-worker). Conductor manages stage ordering, retries, rate limits, decision branches, and HUMAN review gates. Stage 11 (Scorecard) is a Conductor task executed by the worker's scorecard.py handler.
| # | Stage Key | Label |
|---|---|---|
| 01 | RESUME_REGISTERED | Resume Registered |
| 02 | DEDUP_CHECK | Duplicate Check |
| 03 | OCR_LAYOUT | Reading Document Layout |
| 04 | DATA_CLEANING | Cleaning Extracted Text |
| 05 | STRUCTURED_EXTRACTION | Extracting Structured Resume |
| 06 | NORMALIZATION | Normalizing Skills |
| 07 | DATA_FUSION_ENRICHMENT | Data Fusion Enrichment |
| 08 | VALIDATION_GATES | Validation Gates (A through E) |
| 09 | SCORING_INPUT_BUILD | Build Scoring Inputs |
| 10 | GCS_ARCHIVE_MOVE | Move Source to Processed |
| 11 | SCORECARD_GENERATION | Score Against JD |
| 12 | RECRUITER_ARTIFACTS | Build Recruiter Artifacts |
1.5 Component Boundaries
- JD Orchestrator owns: JD authoring, versioning, requirements, must-haves, proficiency/recency targets, AI JD generation
- Resume Parsing Pipeline owns: extraction, evidence mapping, normalization, canonical skill candidates, scoring input snapshot creation
- Scoring Engine owns: gate evaluation, bucket scoring, modifier computation, scorecard persistence, explanations and evidence linkage
- Gemini owns nothing persistently: produces bounded artifacts stored in Postgres and referenced by IDs. Always invoked with
response_schemafor structured output enforcement
Section 2: 8 Scoring Buckets (Formulas and Implementation)
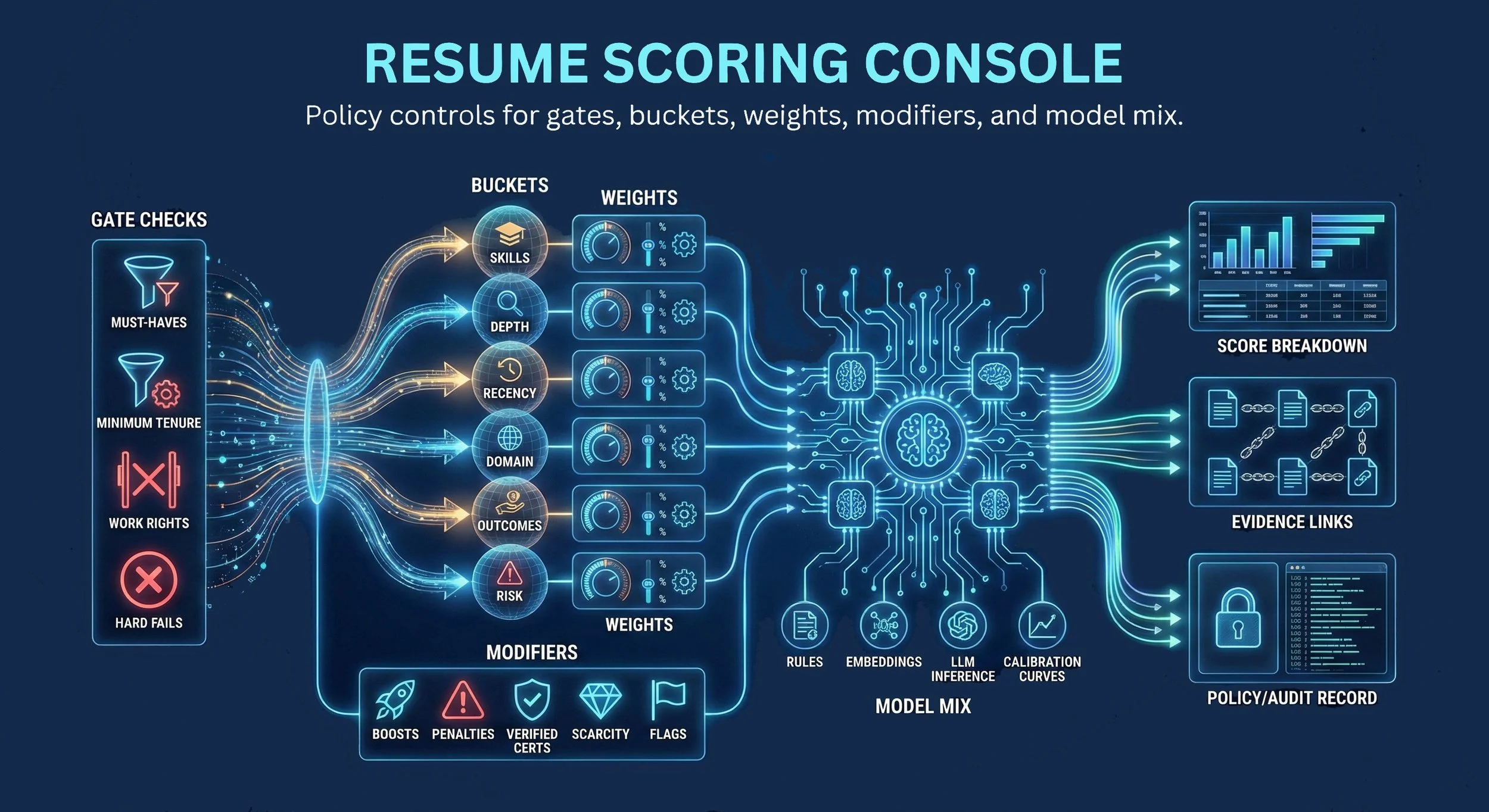
Each bucket produces a score in the range 0–100. Buckets are combined via configurable weights (must sum to 1.0 for enabled buckets) into base_fit. Bucket dispatch uses ScorerRegistry in src/scoring/runtime.py with exact match on bucket_id from the published scoring config.
Default bucket weights (production):
| Bucket | bucket_id | Default Weight |
|---|---|---|
| Hard Skills / Tools | hard_skills_tools | 60% |
| Soft / Behavioral | soft_behavioral | 20% |
| Domain / Process | domain_process | 16% |
| Languages / Communications | languages_comms | 2% |
| Scope / Complexity | scope_complexity | 1% |
| Education / Certifications | education_certs | 1% |
| Tenure / Recency | tenure_recency | configurable |
| Compliance / Scheduling | compliance_scheduling | configurable |
2.1 Hard Skills / Tools (default 60%)
Implementation: _score_bucket_hard_skills
Formula:
score = required_match_rate * 75% + nice_to_have_rate * 25% + quality_bonus (up to +8)Match tiers:
- Exact match: 1.0
- Alias match (via
skill_aliastable): ≥0.85 - Fuzzy match: ≥0.65
Inputs:
- Candidate normalized skills (from
normalization_result) plus certification-expanded skills (fromcertification_skill_map) - JD required and nice-to-have skills (loaded via 3-level fallback; see Section 4)
2.2 Soft / Behavioral (default 20%)
Implementation: _score_bucket_soft_behavioral
Formula:
12 behavioral signals scored from evidence spans
leadership and problem_solving weighted 1.2x (elevated importance)
All other signals weighted 1.0xUses soft signal inference from Gemini (bounded, schema-validated) or deterministic pattern matching from parsed resume text. Signals include: leadership, problem_solving, collaboration, ownership, adaptability, communication, attention_to_detail, initiative, mentoring, strategic_thinking, stakeholder_management, conflict_resolution.
2.3 Domain / Process (default 16%)
Implementation: _score_bucket_domain_process
Formula:
score = title_relevance * 50% + skill_domain_overlap * 30% + industry_continuity * 20%- title_relevance: semantic similarity between candidate's current/recent titles and JD title
- skill_domain_overlap: ratio of JD domain-specific skills present in candidate profile
- industry_continuity: consistency of industry across candidate's work history relative to JD industry
2.4 Languages / Communications (default 2%)
Implementation: _score_bucket_languages_comms
Formula:
score = english_score * 60% + additional_languages * 40%- english_score: CEFR-level assessment from resume text quality (C2=100, C1=85, B2=70, B1=50, A2=30, A1=15)
- additional_languages: bonus for languages matching JD requirements
2.5 Scope / Complexity (default 1%)
Implementation: _score_bucket_scope_complexity
Formula:
score = seniority_score * 60% + scope_signals * 40%Seniority pattern matching:
| Title Pattern | Score |
|---|---|
| Chief / VP | 100 |
| Director | 90 |
| Senior | 80 |
| Manager | 75 |
| Lead | 70 |
| Mid-level (no prefix) | 55 |
| Junior | 35 |
| Intern | 20 |
scope_signals: team size mentions, budget mentions, multi-location/global indicators, cross-functional evidence.
2.6 Education / Certifications (default 1%)
Implementation: src/scoring/education_scorer.py
Tenure decay model:
EducationScore = (DegreeScore x DecayFactor x DegreeWeight) + (SkillsMatchScore x SkillsWeight)
DecayFactor = e^(-0.18 x max(0, YearsExperience - 3))
Combined bucket = education_scorer * 55% + cert_matching * 35% + cert_expanded_skill_bonus * 10%Seniority-aware degree vs skills weighting:
| Seniority | Degree Weight | Skills Weight |
|---|---|---|
| Junior (0–3 years) | 60% | 40% |
| Mid-level (4–7 years) | 40% | 60% |
| Senior (8–12 years) | 25% | 75% |
| Director (13–18 years) | 15% | 85% |
| Executive (19+ years) | 5% | 95% |
Additional factors:
- Field relevance: 1.0 (exact match to JD field) down to 0.5 (no match)
- Skill recency: current = 1.0, 2–4 years = 0.75, 5+ years = 0.50
- Certification bonus: 0.04 per matched cert, capped at 0.12; expiry-aware
- Vendor cert matching: experience-weighted, specializations 1.5x multiplier
2.7 Tenure / Recency
Implementation: _score_bucket_tenure_recency
Formula:
score = years_score * 40% + recency_score * 35% + stability_score * 25%- years_score: total relevant experience years vs JD requirements
- recency_score: how recently the candidate used JD-relevant skills
- stability_score: average tenure per role, penalizing job-hopping patterns
2.8 Compliance / Scheduling
Implementation: _score_bucket_compliance_scheduling
Formula:
score = completeness * 50% + norm_confidence * 30% + gate_health * 20%- completeness: resume section completeness (work history, education, skills all present)
- norm_confidence: average normalization confidence across matched skills
- gate_health: proportion of upstream validation gates that passed
2.9 Scoring Math (Deterministic)
base_fit = SUM(bucket_weight_i * bucket_score_i) for enabled buckets where SUM(weights) = 1.0
modifier_pts = clamp(SUM(modifier_points_j), -budget, +budget)
score_total = clamp(base_fit + modifier_pts, 0, 100)
If DISQUALIFIED: score_total = null, base_fit = null, modifier_points = nullScore band mapping (src/scoring/helpers.py):
| Score Range | Band | Recommendation |
|---|---|---|
| 70–100 | STRONG | ADVANCE |
| 50–69 | BORDERLINE | REVIEW |
| 0–49 | RISK | HOLD |
Section 3: Scoring Gates
Gates are fail-fast rules evaluated before bucket scoring. If any gate with severity DISQUALIFY fails, scoring stops and the scorecard status is set to DISQUALIFIED with score_total = null.
3.1 Gate Types (DSL)
| Type | Description | Example |
|---|---|---|
N_OF_M_SKILLS |
Candidate must possess at least N of M specified skills | Must have 4 of 5 core finance tools |
MIN_VALUE |
Numeric field must meet or exceed a minimum | Minimum 3 years relevant experience |
MAX_VALUE |
Numeric field must not exceed a maximum | Maximum 24 months since last relevant role |
BOOLEAN_TRUE |
Boolean field must be true | Work authorization confirmed |
TIMEZONE_OVERLAP |
Candidate timezone must overlap with required hours | Minimum 4 hours overlap with PH business hours |
3.2 Gate Severities
| Severity | Behavior |
|---|---|
DISQUALIFY |
Stops scoring immediately. Scorecard status = DISQUALIFIED, score_total = null. Failed gates with reasons and evidence are persisted. |
WARN |
Gate failure is recorded but scoring continues. Flagged for recruiter review. |
INFO |
Informational. Recorded in gate results but does not affect scoring or recruiter workflow. |
3.3 Upstream Pipeline Validation Gates
Five gates control pipeline progression before scoring. Each writes a passed boolean to pipeline_gate_result:
| Gate | What It Validates | Status (2026-04-04) |
|---|---|---|
GATE_A_LOSSLESS |
OCR coverage: page map completeness vs source page count | Working correctly |
GATE_B_SCHEMA |
Extraction schema validity against IIR schema. _partition_validation_issues() separates blocking from advisory issues. Gate B fails on blocking errors; intake stops pipeline on failure. |
FIXED (was P0-1: always passed true) |
GATE_C_EVIDENCE |
Evidence span resolution rate per structured field. _validate_extraction_evidence_contract() checks per-section fact coverage with 20% density floor. |
FIXED (was P0-2: only checked list presence) |
GATE_D_DEDUP |
Deduplication result: stops run as DEDUP_SKIPPED if duplicate | Working correctly |
GATE_E_ARTIFACTS |
Meta-gate: URL quality, bbox quality, normalization, work history | Working correctly |
Section 4: JD Skill Requirements Loading
_load_jd_skill_requirements() implements a 3-level fallback to ensure JD skills are available for scoring regardless of how they were authored:
- Level 1:
jd_skill_requirementtable (preferred)- Structured rows with skill_id, importance (required / nice_to_have), proficiency targets, recency constraints
- Written by the JD Orchestrator when requirements are explicitly configured
- Level 2:
job_description_version.extracted_features_json(legacy)- JSONB column containing skills extracted from JD text by earlier pipeline versions
- Used when
jd_skill_requirementrows do not exist for the JD version
- Level 3:
job_description_version.model_json(JD Orchestrator)- Full JD model from the JD Orchestrator UI, containing skills within the structured JD payload
- Ensures skills saved via AI JD Generator are available for scoring even when
jd_skill_requirementrows have not been synced
This three-level fallback guarantees that no matter how a JD was created (manually structured, legacy extraction, or AI-generated), the scoring engine has access to skill requirements.
Section 5: Modifiers
Modifiers are post-bucket point adjustments, bounded and configurable. They are applied after base_fit computation and clamped by per-modifier min_points / max_points and a global modifiers_budget_points.
5.1 Data Fusion Confidence
points = ((avg_norm_confidence - 0.5) / 0.5) * max_points
Where:
avg_norm_confidence = average confidence score across all normalization results
max_points = configured maximum for this modifier (e.g., 3)
Result range: -max_points to +max_points
Confidence 0.5 = 0 points (neutral)
Confidence 1.0 = +max_points (full bonus)
Confidence 0.0 = -max_points (full penalty)5.2 Evidence Coverage JD Duties
points = ((jd_coverage_ratio - 0.5) / 0.5) * max_points
Where:
jd_coverage_ratio = proportion of JD duties evidenced in candidate resume
max_points = configured maximum for this modifier (e.g., 4)
Result range: -max_points to +max_points
Coverage 50% = 0 points (neutral)
Coverage 100% = +max_points (full bonus)
Coverage 0% = -max_points (full penalty)5.3 Modifier Persistence
Each modifier result is persisted to intelletto.modifier_result with: modifier_id, modifier_name, points_awarded, min_points, max_points, basis_json (computation inputs), and evidence_json.
Section 6: Scoring Config Lifecycle
6.1 Config States
DRAFT --> PUBLISHED --> DEPRECATED
| |
| (mutable, editable) | (immutable, frozen)
| |
+--- New DRAFT forked ----->+ (append-only versioning)| State | Behavior |
|---|---|
DRAFT |
Mutable. Can be edited repeatedly. Not eligible for production scoring. |
PUBLISHED |
Immutable. Once published, the config payload is frozen. Eligible for scoring. Any change requires creating a new DRAFT version. |
DEPRECATED |
No longer eligible for new scoring runs. Historical scorecards referencing this config remain intact. |
6.2 Governance Rules
- Append-only versioning: Edits to a PUBLISHED config are rejected. A new DRAFT must be created (optionally cloned from the published version).
- Publish validation gate: Before a config transitions to PUBLISHED, the system validates:
- Enabled bucket weights sum to 1.0 (within tolerance ±0.0001)
- Gate DSL types are supported and schema-valid
- Modifier clamp bounds are consistent
- Prohibited features are not referenced
- Rollback: Reactivates a prior PUBLISHED version for new scoring runs without altering history. All existing scorecards remain associated with the config used at scoring time.
- Runtime enforcement: Scoring runtime rejects non-PUBLISHED configs with
CONFIG_NOT_PUBLISHED.
6.3 Config Payload Shape (JSONB)
{
"gates": [
{
"gateId": "gate_required_skills",
"name": "Required Hard Skills (N-of-M)",
"severity": "DISQUALIFY",
"rule": {
"type": "N_OF_M_SKILLS",
"minRequired": 4,
"skillIds": ["skill_sql", "skill_excel", "skill_o2c", "skill_sap_fi", "skill_oracle_ebs"]
}
}
],
"buckets": [
{"bucketId": "hard_skills_tools", "weight": 0.60, "enabled": true},
{"bucketId": "soft_behavioral", "weight": 0.20, "enabled": true},
{"bucketId": "domain_process", "weight": 0.16, "enabled": true},
{"bucketId": "languages_comms", "weight": 0.02, "enabled": true},
{"bucketId": "scope_complexity", "weight": 0.01, "enabled": true},
{"bucketId": "education_certs", "weight": 0.01, "enabled": true}
],
"modifiers": [
{"modifierId": "data_fusion_confidence", "minPoints": -3, "maxPoints": 3},
{"modifierId": "evidence_coverage_jd_duties", "minPoints": -4, "maxPoints": 4}
],
"modifiersBudgetPoints": 12
}Section 7: Database Schema
All tables reside in the intelletto schema on Cloud SQL PostgreSQL (intelletto-ai, asia-southeast1).
7.1 scorecard_version (primary scoring output)
| Column | Type | Description |
|---|---|---|
scorecard_version_id | UUID PK | Unique scorecard identifier |
tenant_id | UUID | Tenant isolation |
request_id | UUID | Idempotency / correlation |
scoring_config_version_id | TEXT FK | Published config used for this scoring run |
jd_version_id | UUID FK | JD version scored against |
scoring_input_id | UUID FK | Scoring input snapshot reference |
candidate_id | UUID FK | Candidate scored |
job_requisition_id | UUID FK | Job requisition |
status | TEXT | SCORED | DISQUALIFIED | PENDING | FAILED | UPSTREAM_INCOMPLETE |
score_total | NUMERIC | Final clamped score (0–100), null if DISQUALIFIED |
base_fit | NUMERIC | Weighted sum of bucket scores |
modifier_points | NUMERIC | Sum of modifier adjustments |
disqualification_json | JSONB | Failed gates with reasons (null if scored) |
created_at | TIMESTAMPTZ | Append-only: never updated after creation |
7.2 bucket_score (per-bucket breakdown)
| Column | Type | Description |
|---|---|---|
bucket_score_id | UUID PK | Unique bucket score identifier |
scorecard_version_id | UUID FK | Parent scorecard |
bucket_id | TEXT | Bucket identifier (e.g., hard_skills_tools) |
bucket_name | TEXT | Human-readable bucket name |
score | NUMERIC | 0–100 bucket score |
weight | NUMERIC | Configured weight for this bucket |
contribution | NUMERIC | score * weight (contribution to base_fit) |
is_enabled | BOOLEAN | Whether bucket was active for this scoring run |
evidence_json | JSONB | Supporting evidence pointers |
missing_json | JSONB | Expected but not evidenced items |
evidence_status | TEXT | PRESENT | NONE_FOUND | UNAVAILABLE |
not_scored_reason | TEXT | Reason if bucket was skipped (null if scored) |
rubric_applied_json | JSONB | Scorer ID, input hash, evidence hash for reproducibility |
7.3 modifier_result (per-modifier breakdown)
| Column | Type | Description |
|---|---|---|
modifier_result_id | UUID PK | Unique modifier result identifier |
scorecard_version_id | UUID FK | Parent scorecard |
modifier_id | TEXT | Modifier identifier |
modifier_name | TEXT | Human-readable modifier name |
points_awarded | NUMERIC | Points applied (positive or negative) |
min_points | NUMERIC | Configured minimum |
max_points | NUMERIC | Configured maximum |
basis_json | JSONB | Computation inputs (e.g., avg_norm_confidence, jd_coverage_ratio) |
evidence_json | JSONB | Supporting evidence |
7.4 scoring_gate_result (per-gate evaluation)
| Column | Type | Description |
|---|---|---|
scoring_gate_result_id | UUID PK | Unique gate result identifier |
scorecard_version_id | UUID FK | Parent scorecard |
gate_code | TEXT | Gate identifier from config |
status | TEXT | PASS | FAIL | SKIPPED |
severity | TEXT | DISQUALIFY | WARN | INFO |
evidence_status | TEXT | PRESENT | NONE_FOUND | UNAVAILABLE |
7.5 scoring_config_version (config governance)
| Column | Type | Description |
|---|---|---|
scoring_config_version_id | TEXT PK | Human-readable version ID |
tenant_id | UUID | Tenant isolation |
status | TEXT | DRAFT | PUBLISHED | DEPRECATED | ROLLBACK |
config_payload | JSONB | Complete config: gates, buckets, modifiers, budget |
published_at | TIMESTAMPTZ | When config was published (null if DRAFT) |
deprecated_at | TIMESTAMPTZ | When config was deprecated (null if active) |
created_at | TIMESTAMPTZ | Row creation time |
7.6 scoring_run_metering (operational telemetry)
| Column | Type | Description |
|---|---|---|
scoring_run_metering_id | UUID PK | Unique metering record |
scorecard_version_id | UUID FK | Scored scorecard |
scoring_config_version_id | TEXT FK | Config used |
score_run_count | INT | Run counter |
gate_evaluations | INT | Number of gates evaluated |
bucket_computations | INT | Number of buckets computed |
modifier_computations | INT | Number of modifiers computed |
gemini_calls | INT | AI inference calls (typically 0 for scoring) |
gemini_tokens_in | BIGINT | Input tokens |
gemini_tokens_out | BIGINT | Output tokens |
db_writes | INT | Database write operations |
latency_ms_load_inputs | INT | Input loading latency |
latency_ms_gates | INT | Gate evaluation latency |
latency_ms_buckets | INT | Bucket computation latency |
latency_ms_modifiers | INT | Modifier computation latency |
latency_ms_persist | INT | Persistence latency |
latency_ms_total | INT | Total scoring run latency |
recorded_at | TIMESTAMPTZ | When metering was recorded |
7.7 Related Pipeline Tables
The scoring engine consumes data from these upstream tables (read-only during scoring):
scoring_input_snapshot— immutable scoring handoff payload with normalized skills, work history, education, certifications, languages, gate statusparsed_resume— structured extraction output with sections_json, extraction_json, evidence_spans_jsonnormalization_result— canonical skill mappings (raw_term → canonical_skill_id with match_type and confidence)pipeline_gate_result— gate pass/fail outcomes per pipeline run (Gates A through E)enrichment_payload— data fusion resultscandidate_profile— canonical candidate record
Section 8: API Endpoints (v3)
All endpoints are served from the v3 application on Cloud Run. API namespace: /api/v3/.
8.1 Core Scoring Endpoints
| Method | Endpoint | Description |
|---|---|---|
| POST | /api/v3/pipeline/rescore/{document_id} |
Re-score a single document. Append-only (creates new scorecard_version). Supports JD override and config version override. |
| POST | /api/v3/pipeline/rescore/bulk |
Bulk re-score multiple documents. Same append-only semantics. |
8.2 Scoring Analysis Endpoints
| Method | Endpoint | Description |
|---|---|---|
| GET | /api/v3/scoring/interview-brief/{scorecard_version_id} |
Evidence-derived interview brief: technical gap probes, behavioral signals, risk flags. No Gemini; deterministic from scorecard data. |
| GET | /api/v3/scoring/comp-inference |
Compensation inference: P25/P50/P75 estimates by seniority, country, and industry. |
| GET | /api/v3/scoring/jd-calibration/{jd_version_id} |
JD difficulty calibration: score distribution analysis and difficulty index for a given JD. |
| POST | /api/v3/scoring/decision |
Recruiter feedback signal loop: record ADVANCE/HOLD/REJECT decisions with reasons. |
| GET | /api/v3/scoring/decisions/{scorecard_version_id} |
Retrieve recruiter decisions for a scorecard. |
8.3 Internal Pipeline Endpoints (v1 bridge)
The pipeline internal endpoints are served via the v3 v1-native bridge (v3/src/api/middleware/v1_proxy.py). Key scoring-related internal routes:
| Method | Endpoint | Description |
|---|---|---|
| POST | /internal/v1/scoring/build_inputs |
Build scoring input snapshot from pipeline run outputs |
| POST | /api/v1/scoring/scorecards |
Execute scoring runtime: gates, buckets, modifiers, persist scorecard |
8.4 Example API Payloads
Score Request (via pipeline)
POST /api/v1/scoring/scorecards
{
"scoringConfigVersionId": "scv_2026_04_01_0001",
"jdVersionId": "jdv_01J4QZ0B1J8A1D7S3H3F2C9M11",
"parsedResumeId": "pr_01J4QZ2Z1S5JZ9RZB9E1A2B8C3",
"runMode": "PERSIST",
"requestId": "req_01J5A1B2C3D4E5F6G7H8"
}Response (SCORED)
{
"scorecardId": "sc_01J5S2K7A2T9K3H8Q6D1E4F7G9",
"status": "SCORED",
"scoreTotal": 82.6,
"baseFit": 79.4,
"modifierPoints": 3.2,
"scoringConfigVersionId": "scv_2026_04_01_0001",
"jdVersionId": "jdv_01J4QZ0B1J8A1D7S3H3F2C9M11",
"parsedResumeId": "pr_01J4QZ2Z1S5JZ9RZB9E1A2B8C3",
"gates": [
{"gateId": "gate_required_skills", "status": "PASS"},
{"gateId": "gate_timezone_overlap", "status": "PASS"}
],
"bucketScores": [
{
"bucketId": "hard_skills_tools",
"score": 88,
"weight": 0.60,
"contribution": 52.8,
"evidence": [
{
"type": "SKILL_MENTION",
"skillId": "skill_sql",
"confidence": 0.91,
"matchType": "EXACT"
}
],
"missing": [
{"skillId": "skill_sap_fi", "reason": "not evidenced within recency window"}
]
}
],
"modifiers": [
{"modifierId": "data_fusion_confidence", "points": 1.2, "basis": {"avgNormConfidence": 0.82}},
{"modifierId": "evidence_coverage_jd_duties", "points": 2.0, "basis": {"coveragePct": 0.74}}
],
"metering": {
"score_run_count": 1,
"gemini_calls": 0,
"db_writes": 6,
"latency_ms_total": 187
}
}Response (DISQUALIFIED)
{
"scorecardId": "sc_01J5S2M1P0K9N7B6C4D3E2F1A0",
"status": "DISQUALIFIED",
"scoreTotal": null,
"baseFit": null,
"modifierPoints": null,
"disqualification": {
"failedGates": [
{
"gateId": "gate_required_skills",
"severity": "DISQUALIFY",
"reason": "N_OF_M_SKILLS_NOT_MET",
"details": {"minRequired": 4, "met": 2},
"evidence": []
}
]
},
"metering": {
"score_run_count": 1,
"gemini_calls": 0,
"db_writes": 3,
"latency_ms_total": 42
}
}Section 9: Enhancement Endpoints (All Delivered)
All enhancement endpoints are live on Cloud Run. They extend the core scoring with analytical and recruiter-facing capabilities.
| Category | Endpoint | Description | Status |
|---|---|---|---|
| Interview Brief | GET /api/v3/scoring/interview-brief/{id} |
Evidence-derived interview probes: technical gaps, behavioral signals, risk flags. No Gemini. | Delivered |
| Authenticity Score | GET /api/v3/candidates/{id}/authenticity |
Date coherence, title inflation, employment gaps, career plausibility, skill density analysis. | Delivered |
| Sector Profile | GET /api/v3/candidates/{id}/sector-profile |
15 NAICS-style sectors with sector continuity score. | Delivered |
| Bias Audit | GET /api/v3/candidates/{id}/bias-audit |
Age inference + gender-coded language detection. Advisory only, never used in scoring. | Delivered |
| Compensation Inference | GET /api/v3/scoring/comp-inference |
P25/P50/P75 compensation estimates by seniority, country, and industry. | Delivered |
| JD Calibration | GET /api/v3/scoring/jd-calibration/{id} |
Score distribution + difficulty index for a JD. Helps recruiters understand role competitiveness. | Delivered |
| Cross-JD Fit | GET /api/v3/candidates/{id}/cross-jd-fit |
Multi-JD matching: scores candidate against multiple open JDs simultaneously. | Delivered |
| Recruiter Feedback | POST /api/v3/scoring/decision |
Recruiter decision feedback loop: ADVANCE/HOLD/REJECT with structured reasons. | Delivered |
| Cover Letter Sentiment | POST/GET /api/v3/candidates/{id}/cover-letter |
Cover letter analysis with sentiment scoring. | Delivered |
| Pipeline Latency | GET /api/v3/pipeline/latency-report |
Pipeline latency SLA reporting across all stages. | Delivered |
Remaining (external dependencies):
- GitHub structured analysis: requires GitHub API integration
- LinkedIn enrichment via Proxycurl: requires API key procurement
Section 10: Scoring Runtime Workflow
10.1 Execution Lifecycle
1. INPUT RESOLUTION
Load scoring config version (must be PUBLISHED)
Load JD version + parsed resume + scoring input snapshot
Validate required upstream gates passed
2. GATE EVALUATION (fail-fast)
For each gate in config:
Evaluate DSL rule against inputs
If DISQUALIFY gate fails --> DISQUALIFIED (stop, persist, return)
Record all gate results regardless of outcome
3. BUCKET SCORING (0..100 each)
For each enabled bucket:
Dispatch to ScorerRegistry (exact match on bucket_id)
Compute deterministic score from evidence
Record evidence_json, missing_json, rubric_applied_json
4. MODIFIER COMPUTATION
For each modifier:
Compute points from basis inputs
Clamp by per-modifier min/max
Sum all modifier points, clamp by global budget
5. ASSEMBLY
base_fit = weighted sum of bucket scores
score_total = clamp(base_fit + modifier_points, 0, 100)
Map to band: STRONG / BORDERLINE / RISK
6. PERSISTENCE (transactional BEGIN/COMMIT)
Insert scorecard_version
Insert bucket_score[] rows
Insert modifier_result[] rows
Insert scoring_gate_result[] rows
Insert scoring_run_metering
Emit pipeline_phase_event (telemetry)
7. RETURN scorecard with full breakdown10.2 Code Path
- Scoring handoff:
/internal/v1/scoring/build_inputs— takesparsed_resume_idor resolves from pipeline run. Createsscoring_input_snapshot. - Input snapshot:
_ensure_scoring_input_snapshot()— loads parsed resume, pipeline run, page map, canonical extraction, normalization, gate status. Hard-blocks if required gates missing/failed. - Runtime entrypoint:
/api/v1/scoring/scorecards— resolves published config, loads JD + parsed resume + scoring input, starts scoring run. - Gate evaluation:
_evaluate_gate()for each gate in config. - Bucket dispatch:
ScorerRegistryinsrc/scoring/runtime.py— exact match on bucket_id from config. - Modifier computation: Two heuristic modifiers: data fusion confidence and JD coverage ratio.
- Persistence: Transactional BEGIN/COMMIT. Writes:
scorecard_version,scoring_gate_result,bucket_score(with realrubric_applied_json),modifier_result, metering, audit events.
10.3 Idempotency
Every scoring operation that writes data checks idempotency_record first:
existing = await db.fetchrow(
"SELECT id FROM intelletto.idempotency_record WHERE key = $1",
idempotency_key
)
if existing:
return {"status": "already_processed", "id": str(existing["id"])}Silent double-writes corrupt the audit trail and are prevented by this guard.
10.4 Re-scoring
Re-scoring is append-only: it creates a new scorecard_version row. Prior scorecards are never overwritten. The re-scoring API supports:
- JD override (score against a different JD version)
- Config version override (use a different published scoring config)
- Single document:
POST /api/v3/pipeline/rescore/{document_id} - Bulk:
POST /api/v3/pipeline/rescore/bulk
Section 11: Environment and Deployment
| Resource | Value |
|---|---|
| Runtime | Google Cloud Run (API + Worker) |
| Pipeline Orchestration | Netflix Conductor OSS 3.15.0 on GCE (34.124.211.14:8080) |
| Worker Service | intelletto-worker on Cloud Run (HTTP-based task polling, always-on) |
| Production URL | api.intelletto.ai |
| Cloud SQL Instance | intelletto-ai |
| Cloud SQL Region | asia-southeast1 |
| Primary Schema | intelletto |
| Table Count | ~169 |
| v3 Entry Point | v3/main.py |
| v3 App Factory | v3/src/api/app.py |
| v3 Local Dev | http://localhost:8080 |
| v3 Scoring Domain | v3/src/domains/scoring/ |
| Scorer Registry | src/scoring/runtime.py |
| Education Scorer | src/scoring/education_scorer.py |
| GCS Intake Path | gs://<bucket>/RESUME-POOL/ |
| GCS Processed Path | gs://<bucket>/RESUME-POOL/processed/ |
| Gemini Model | gemini-2.5-flash (via Vertex AI, always with response_schema) |
| Test Suite | 747 tests (v3: 101, v2 reference: 327, integration: 319) |
| Goldens Corpus | v3/goldens/ (31/36 within 5 pts of v2 parity) |
| Current Revision | 276+ |
11.1 Technology Stack
- Backend: Python + FastAPI (async/await throughout)
- Database: PostgreSQL on Cloud SQL (asyncpg connection pool)
- AI: Google Gemini 2.5 Flash via Vertex AI for bounded inference only (extraction, normalization, soft signals). Always with
response_schemaenforcement. Never for scoring math. - OCR: Google Document AI for layout parsing
- Storage: Google Cloud Storage for resume file ingestion and archival
- Orchestration: Netflix Conductor OSS — durable workflow execution with per-task retries, rate limits, timeouts, and HUMAN review gates
- Deployment: Cloud Run (API + Worker). Conductor on GCE.
- Secrets: Google Secret Manager (INTELLETTO_DB_URL, GEMINI_API_KEY, API_KEY)
Section 12: Known Gaps and P0 Status
| ID | Description | Status (2026-04-04) | Resolution |
|---|---|---|---|
| P0-1 | Gate B Schema: was always passing passed=True regardless of extraction quality |
FIXED | _partition_validation_issues() separates blocking from advisory. Gate B fails on blocking errors. Intake stops pipeline on failure. 6 new tests. |
| P0-2 | Gate C Evidence: was True if evidence_spans else False (list presence only, not per-fact) |
FIXED | _validate_extraction_evidence_contract() checks per-section fact coverage with 20% density floor. 9 new tests. |
| P0-3 | Bucket dispatch + rubric persistence: Dispatch now via ScorerRegistry (exact match, not substring). _deterministic_float removed. rubric_applied_json has real scorer_id/input_hash/evidence_hash. |
PARTIAL | Dispatch and persistence are correct. Remaining gap: scorers are inline heuristic functions, not configurable rubric rules loaded from config. Closing this requires the full rubric-from-config implementation per the scoring spec. 16 tests. |
12.1 What P0-3 Partial Means
The current system scores correctly using inline Python heuristics per bucket. Each scorer is registered in ScorerRegistry and dispatched by exact bucket_id match. The rubric_applied_json records the scorer_id and input/evidence hashes for reproducibility.
What is not yet implemented: loading rubric rules from the config_payload JSONB and applying them dynamically. Today, the rubric definitions in config are stored but the actual scoring logic is the inline Python implementation. This means changing scoring behavior requires code changes, not just config changes.
Do not attempt to close P0-3 without reading the full scoring spec and understanding the rubric DSL requirements.
Section 13: Non-Negotiable Invariants
- Gate-first: Hard disqualifications run before scoring. If DISQUALIFIED, score_total = null and status = DISQUALIFIED. No bucket or modifier computation occurs.
- Deterministic scoring: No stochastic scoring steps. Gemini only for bounded inference with schema validation and replayable inputs. Given the same (scoring_config_version_id, jd_version_id, parsed_resume_id), the system produces the same scorecard every time.
- Append-only versioning: Re-scoring creates a new immutable scorecard version. Prior scorecards are never overwritten or deleted.
- Evidence required: Every scored or disqualifying decision must carry evidence pointers (or explicit
evidence_status = NONE_FOUNDwith search criteria recorded). - Compliance: Protected attributes (race, ethnicity, religion, age, sex, gender identity, health, disability, family status) are never used as scoring features. Prohibited feature list is enforced at ingestion and scoring runtime.
- Config immutability: Published configs are frozen. Any change requires a new DRAFT version. Scoring runtime rejects non-PUBLISHED configs.
- Idempotency: Every pipeline write checks
idempotency_recordfirst. Duplicate scoring requests return the existing scorecard without creating duplicate rows. - Audit trail: Every scoring run writes to
pipeline_phase_event,scoring_run_metering, and creates immutable rows in all scoring tables. Failed runs are recorded, not silently swallowed. - Bucket weight invariant: Enabled bucket weights must sum to 1.0 (within tolerance of 0.0001). Config validation enforces this before publish.
- Scorer registry contract: Bucket dispatch uses exact match on
bucket_idviaScorerRegistry. No substring matching, no fallback logic.
13.1 Scoring System Safety Rules
- NEVER modify
_score_bucket_*heuristic scorers without reading the full scoring spec - NEVER change gate threshold values without reading the scoring config
- NEVER modify bucket weights without rubric alignment
- NEVER re-run scorecard generation for already-scored resumes without confirmation
- NEVER call
/api/v1/scoring/scorecardson a resume that has a completedscorecard_versionwithout using the re-score API
13.2 Lossless Resume Output Constraints
- NEVER produce: "No detailed achievements mapped in this parse." — this is always a defect
- NEVER truncate experience sections for any reason
- NEVER omit advisory roles, even those outside the main employment timeline
- NEVER omit education or certifications — if absent from source, write "Not captured in source document"
- NEVER treat normalization output as a replacement for source narrative content
- The Intelletto Resume word count must always exceed the source resume word count
Appendix A: Trial E2E Results (2026-04-02)
Full end-to-end pipeline validation with production data:
- 218 documents imported → 218/218 COMPLETED → 218/218 scored
- 0 failures, 0 zero-skill candidates
- All 12 pipeline stages ran for each document
- JD 59A356 (Senior Education Specialist): top score 79.8
- JD 479B1D (Sales Manager): top score 83.5
Concentrix demo dataset: 2,483 resumes across 24 AI-generated JDs, Filipino candidate profiles, full pipeline processing.
Version 1.0.0 — 2026-04-04 — Production System Reference