
Most résumés don’t get read.
We’re trying to fix that.
Intelletto plugs into the ATS you already run. It reads every résumé that lands there, scores it against the actual job you posted, and tells you why — with the source passage attached, so a regulator (or a hiring manager, or the candidate themselves) can check the work.

per Hire
to Fill
Cost
Capacity
Three things. One underlying engine.
You can think of Intelletto as three products that share a single pipeline and a single audit trail. Most teams turn one on first — usually Talent — and add the others as the value compounds. None of them require a replatform.
shortlist
saved
negatives ↓
uplift
ramp
↓
NPS
auditable
at any stage
We plug in. Nothing else changes.
Two sides of the same commitment. No new system for anyone to log into. And no automated decisions until your team has watched the model long enough to trust it.
Gated. Recommendations now show up in the recruiter’s view, but every one needs a human approve / edit / decline. Every override the human makes gets logged and feeds the model.
Automate. Only on the requisitions you say so, only above the confidence threshold you set. Pull the threshold back any time. There is no one-way door.
How a résumé turns into a score you can defend.
stages
gates
buckets
modifiers
modes
Twelve stages. Five quality gates.
The first four stages answer four boring questions — what document, who owns it, have we seen it, what does the page actually say. The middle stages do the AI work. The last stages produce the artefacts a recruiter looks at. Same path, every time.

Five questions we ask before a score is allowed to happen.
A score that came out of broken inputs is worse than no score — it’s a number someone will trust. So before the scorer runs, every candidate has to pass five gates. Two of them are hard stops. Two are warnings the recruiter sees. One is a quality summary attached to the artefact. Whatever happens, every verdict ends up in the audit packet.
| Gate | What it asks | If the answer is no | Verdict |
|---|---|---|---|
| A · Lossless | Did the OCR actually read every page? Did anything drop silently? | Flag it. A human re-reads. Pipeline continues. | WARN |
| B · Schema | Did the AI return the exact JSON shape we asked for? | Hard stop. A malformed extraction is not allowed to become a score. | BLOCK |
| C · Evidence | Does every claim trace back to a passage in the source document? | Show the low-evidence claims to the recruiter. They decide. | WARN |
| D · Dedup | Have we already processed this person in your pool? | End the run as a duplicate. The original record stays untouched. | BLOCK |
| E · Artefacts | URL quality, bounding boxes, normalisation hits, work history present? | Attach a quality summary. The score stays visible. | PASS |
AI isn’t a feature here. It’s running in about two dozen places.
Most platforms bolt AI onto one step — usually résumé parsing — and call it done. We use structured-output AI all the way across the hiring loop. Every call is locked to a schema and bound to an evidence contract, so we get back something we can actually use (not just “text the AI made up”).
Nine buckets. Four seniority profiles.
Here’s the awkward thing about generic scoring engines: a graduate engineer and a COO can’t share the same rubric. What gets a junior shortlisted is not what gets a chief operating officer shortlisted. So we don’t make them share. The same nine buckets exist for every role, but the weights flip as the job gets more senior. “Can you do the work?” becomes “can you scale the work?” becomes “can you own the function?” becomes “can you stand behind it?”
| Band | Hard | Leadership | Domain | Modifier Budget |
|---|---|---|---|---|
| Junior / Mid | 55% | 10% | 10% | ±8 pts |
| Senior / Lead | 45% | 15% | 15% | ±10 pts |
| Director / VP | 30% | 20% | 20% | ±14 pts |
| C-Level / Exec | 15% | 30% | 25% | ±16 pts |
We fix it by linking 200+ industry-recognised certifications back to their underlying skill basket through the DoL occupation taxonomy. If you hold the credential, you carry its skills with you — at a confidence-weighted match that reflects how recent the cert is and how tightly it maps to the requirement. Nobody gets penalised because their narrative was tight rather than exhaustive.
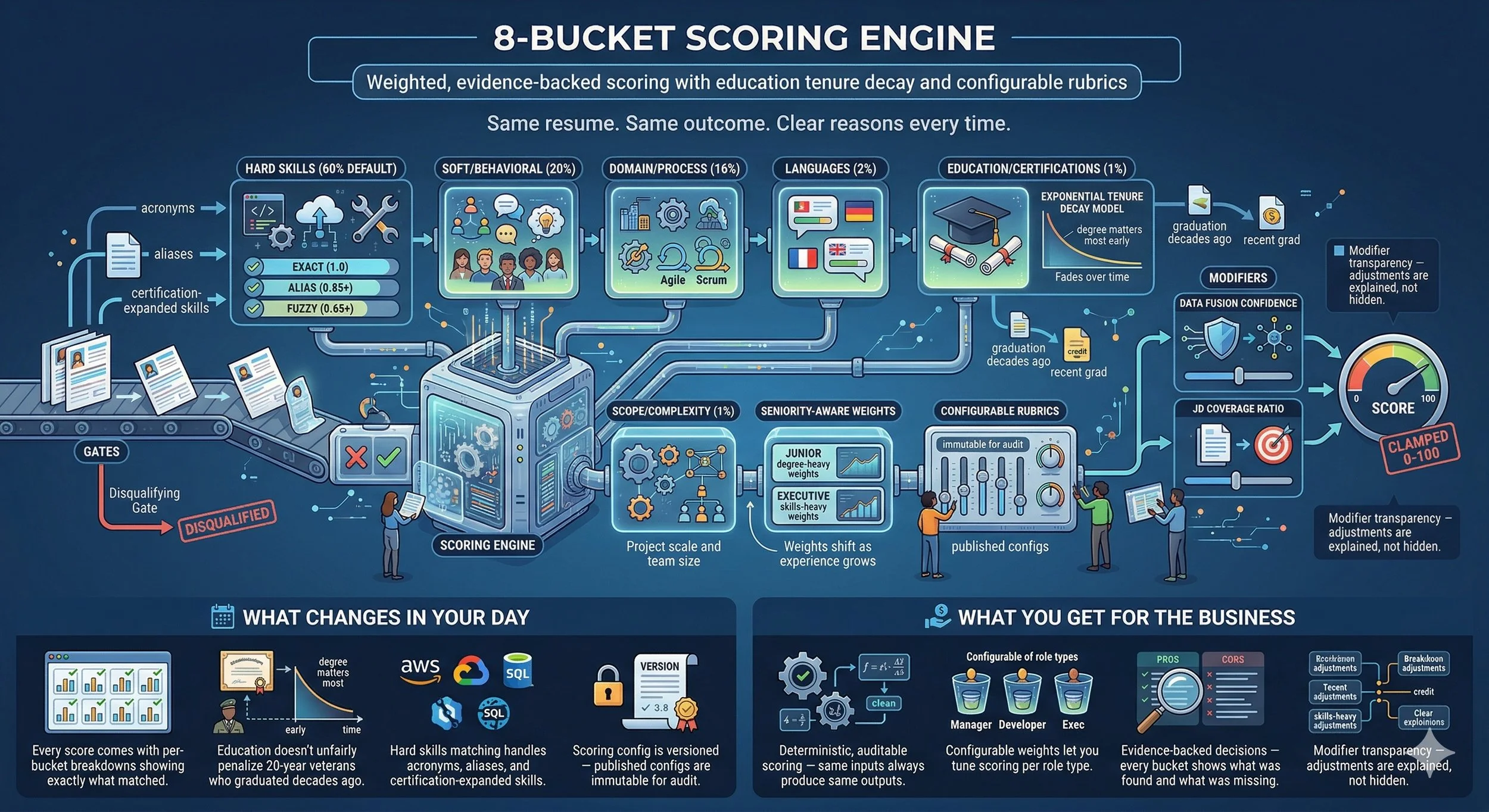
The bits the base score can’t see on its own.
The base score is “how well do their skills line up with the requirements?” That’s a real question, but it’s not the whole question. Five modifiers add and subtract from the base to catch evidence quality, quantified outcomes, and two flavours of risk. Every one of them is itemised on the scorecard — a recruiter can see exactly which modifier shifted the score by how many points and why.
Every word the AI writes gets read by a different AI.
One thing worth being clear about: the auditor only looks at what Intelletto wrote. Not the candidate’s résumé. Not the hiring manager’s notes. Just the AI-generated text — job descriptions, outreach drafts, score rationale. If it spots loaded language, it surfaces the finding and suggests a rewrite. A human always decides what to do with it. It never blocks the work, and every finding gets logged.
One quirk worth knowing. A finding on a JD or an outreach draft turns into a rewrite suggestion you can accept or ignore. A finding on score rationale is annotated, never overwritten — because the scorecard is immutable evidence and we’re not in the business of rewriting history.
Pick the path that matches how you actually hire.
Same twelve stages, four different paths through them. The mode is a per-requisition (or per-source, or per-team) choice. You can use all four in the same week without anyone’s permission.
| Mode | What it does | Use when… | Ends in |
|---|---|---|---|
| A · Pool Prep | Read, normalise, gate — don’t score yet. | You’re building a pool of pre-qualified people for roles you haven’t opened yet. | POOL_READY |
| B · Pool Activation | Take a pool candidate and score them against a JD that just opened. | A req opens, you already have great candidates in your pool, you want answers in minutes. | PROCESSED |
| C · Full Auto | The whole thing: read, score, shortlist, in one pass. | Standard inbound for a live req. The most common path. | PROCESSED |
| D · Bulk Import | High-volume ingest, plus a clean Intelletto-format résumé per person. | You’re migrating from another ATS, importing an agency dump, or absorbing a historical pool. | POOL_READY |
The modes are just the start. Skill taxonomy, bucket weights, auto-score thresholds, knockout criteria, RBAC permissions, culture-fit pillars — everything that matters is configurable per-tenant. We’re not trying to impose a hiring philosophy on you. You bring the philosophy. Intelletto executes it.
Five reasons every Intelletto score holds up when someone asks “why?”
The person being scored, the manager doing the hiring, and the regulator reviewing the process all eventually ask the same question: where did this number come from? A scoring engine that can’t answer that question shouldn’t be making recommendations about people’s careers. Here’s how Intelletto answers it.
SHA256-hashed. There is no “trust us” step.scorecard_version alongside the old one. The original score, the original
snapshot, and the original rubric all stay intact.SHA256 chain from PDF to score, the pipeline stage outcomes, the
rescore history. Recruiters open it inline. Auditors download the signed bundle and
run our open-source verifier — on their own machine, against the immutable input
snapshot — and get back a single line: VERIFIED. That’s the bar.
Not “trust our signature”: re-run the scoring yourself and see you get the
same number.Not an afterthought. Not a checklist someone fills in after launch.
Security, privacy, fairness, reliability. The four words every enterprise software page lists in the footer. Worth saying what they actually mean here.